Upnode Security Architecture


Reliability and Redundancy
Upnode utilizes an active-standby validator setup across different geographic regions to enhance reliability and redundancy. For our routine maintenance, we will first reroute traffic to our standby server before carrying out maintenance on the active server.
Both datacenters operate on distinct architectures. Datacenter 1 utilizes nodes within Proxmox VMs, offering a notable advantage in node isolation. In contrast, Datacenter 2 employs Ubuntu bare metal, optimized for high-performance and low-latency tasks.
By default, we rely on our Ubuntu bare metal as the primary active node due to its superior performance and minimal latency. However, should any issues arise that compromise the Ubuntu system, we have a backup server. This backup is safeguarded by the robust node isolation provided by virtualization, reducing the likelihood of concurrent system crashes.

Security
We use the YubiHSM2 hardware security module to securely store private keys and sign the validated block if supported by the validator software of that chain. However, if YubiHSM2 is not officially supported yet, we use YubiKey to store the SSH key of our validator node and restrict access to our validator server to only a few operators.
Upnode prioritizes server security through a layered approach. An IP whitelist is implemented to ensure that only trusted IP addresses can access the system. User permissions are set up to ensure that each operator has only the necessary rights to perform their tasks. Above all, the entire infrastructure is guarded under the Fortigate 200F hardware firewall VPN. This means any access attempt, regardless of the method, must first authenticate through this fortified VPN barrier, adding an additional layer of defense against intrusions.
Access to the validator infrastructure is via a VPN network through an enterprise-grade Fortigate 200F hardware firewall. All servers run advanced firewalls and only essential ports are exposed.
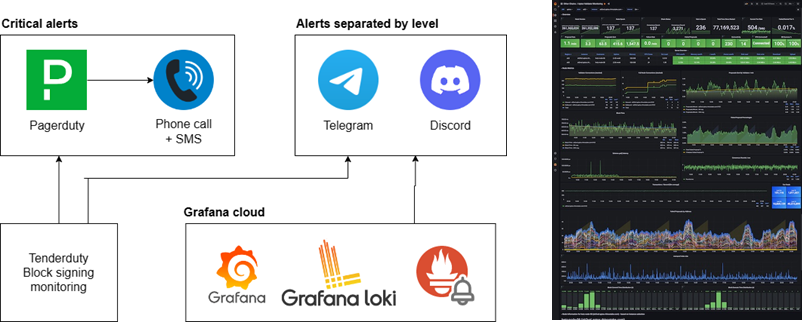
Monitoring and Alerting
We have implemented a robust and comprehensive monitoring stack, incorporating TenderDuty, Grafana, Loki, and Prometheus Alertmanager. This powerful combination allows us to effectively monitor the health and performance of our infrastructure. In the event of any incidents or anomalies, alerts are promptly generated and sent to PagerDuty, which serves as a centralized incident management platform.
PagerDuty is set up to alert our engineers, who are available 24/7, by calling and sending SMS, to look into any issues promptly and ensure they are resolved as quickly as possible.


We have implemented these monitoring and alerting services:
- TenderDuty
- Prometheus
- Grafana
- Healthchecks.io
- PagerDuty
- Telegram
- Discord bot uptime alerts
We have two engineers working in different timezones. When an incident occurs, both will be on-call. Whoever is working at the time will address the issue 24/7.
Team Experience
We are a team of experienced node operators and blockchain developers with over 30 years of combined experience in Web 2.0 and Web 3.0 deployments. We have a track record in the development of and contributions to multiple tools to support our node operations.
We were awarded the Optimism Grant in Cycle 14 to build Upnode Deploy, an all-in-one API Deployment Tool for web3 developers. Please see our proposal at https://app.charmverse.io/op-grants/page-5705679072018564.